上海疫情数据创新高峰,上海疫情数据统计
上海疫情数据创新高峰现状分析
1.1 上海疫情数据趋势变化及峰值特征
- 上海疫情数据在2022年4月达到前所未有的高度,成为全国关注的焦点。
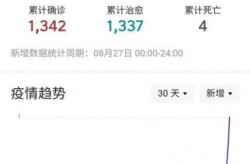
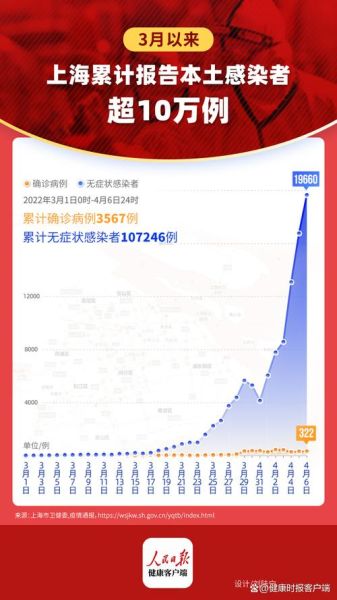
- 从3月到5月,累计报告本土确诊病例超过5万例,无症状感染者高达59万例,疫情形势严峻。
- 确诊+无症状数量在4月7日至4月18日间曾短暂下降,但随后又出现反弹,显示出疫情波动性较大。
- 新增确诊数据比整体数据滞后一周左右,4月13日出现明显增长,4月15日达到峰值,之后逐渐回落。
- 4月22日后,部分区域数据再次上升,表明疫情控制仍面临挑战。
1.2 各区域疫情数据分布与动态变化
- 浦东区、闵行区和黄浦区是疫情最严重的区域,合计占比超过一半,主要集中在闭环隔离管控中。
- 金山区、崇明区、闵行区、普陀区、嘉定区等区域在高峰期后逐步趋于平稳,新增病例大幅减少。
- 浦东区、虹口区的数据仍然较高,4月22日出现反弹,说明这些区域仍是防控重点。
- 松江区在4月22日单日新增超2000例,增速较快,需要特别关注其后续发展。
- 区域间差异明显,部分区域已经进入低发期,而另一些区域仍在高位运行。
1.3 疫情数据统计中的关键指标解读
- 累计罹患率0.23%,意味着每千人中有约2.3人感染,显示疫情覆盖范围较广。
- 无症状感染比例高达91.05%,说明大部分感染者未表现出明显症状,增加了防控难度。
- 感染率为2.52%,表明疫情传播速度较快,需持续加强监测和管理。
- 病死率为1.01%,反映出疫情对高风险人群的影响依然存在,医疗系统压力较大。
- 数据统计不仅反映疫情现状,也为政策制定和资源调配提供重要依据。
上海疫情数据统计与实时更新机制
2.1 上海疫情数据的采集与标准化处理
- 上海疫情数据的采集工作由多个部门协同完成,涵盖医院、社区、隔离点等多个渠道。
- 数据预处理是确保准确性的重要环节,包括时间字段的标准化和区域名称的统一。
- 区域来源数据的字段名被调整为中文,便于公众理解和分析。
- 通过统一的数据格式,提升了数据的可比性和分析效率。
- 标准化处理不仅提高了数据质量,也为后续的统计和预测提供了可靠基础。
2.2 实时更新系统在疫情防控中的作用
- 实时更新系统是疫情防控的重要工具,帮助相关部门快速掌握疫情动态。
- 每日发布的疫情数据让公众能够及时了解最新情况,减少恐慌情绪。
- 数据的透明度提升,增强了政府与民众之间的信任关系。
- 实时更新系统支持多平台访问,方便不同用户获取信息。
- 在疫情高峰期,实时数据的发布频率提高,确保信息的及时性和准确性。
2.3 数据透明度与公众信息获取渠道
- 上海市政府通过官方网站、社交媒体等渠道定期发布疫情数据。
- 公众可以通过多种方式获取疫情信息,包括手机应用、新闻发布会等。
- 数据透明度的提升有助于公众做出科学判断,合理安排生活。
- 部分数据还通过第三方平台进行二次传播,扩大了影响力。
- 信息获取渠道的多样化,使得更多人能够及时掌握疫情动态,增强社会应对能力。
上海疫情数据预测与未来趋势展望
3.1 历史数据与预测模型的对比分析
- 上海疫情数据的历史变化显示,确诊和无症状感染人数在4月中旬达到峰值。
- 预测模型基于历史数据进行建模,试图捕捉疫情发展的规律和趋势。
- 早期预测认为疫情将在4月10日后逐步下降,但实际数据波动较大,与预测存在偏差。
- 部分模型未能准确反映实际情况,导致预测结果与现实不符。
- 数据的复杂性和不确定性使得预测模型需要不断调整和优化。
3.2 不同机构对上海疫情的预测差异
- 兰州大学发布的预测系统曾预计疫情将在5月初得到控制,但后续数据表明这一预测过于乐观。
- 上海交通大学和南开大学的研究团队也发布了类似预测,认为疫情将在4月中旬迎来拐点。
- 不同机构的预测结果存在明显差异,反映出模型假设和数据来源的不同。
- 一些预测结果在实际数据面前被修正,说明疫情发展具有高度不确定性。
- 公众对不同预测结果的关注度提升,也反映出对疫情走向的高度关切。
3.3 未来疫情走势的可能影响因素与应对策略
- 疫情走势受多种因素影响,包括防控措施、人口流动、疫苗接种率等。
- 当前浦东区和虹口区的数据仍处于高位,可能成为未来疫情反弹的风险点。
- 松江区的单日新增病例增长迅猛,需重点关注其发展趋势。
- 应对策略应结合区域特点,采取差异化防控措施,避免一刀切。
- 未来需持续关注数据变化,及时调整政策,确保疫情防控的有效性。
(上海疫情数据创新高峰,上海疫情数据统计)
本文系作者个人观点,不代表创业门立场,转载请注明出处!